|
RDFAnalysis
0.1.1
Physics analysis with ROOT::RDataFrame
|
|
RDFAnalysis
0.1.1
Physics analysis with ROOT::RDataFrame
|
The Node class acts as a wrapper around the ROOT::RDF::RNode class. It provides a similar interface for Filter, Define and Fill. Most of the other actions are not currently implemented but they can easily be added in.
In order to create the root node of your computational tree you should use the createROOT function. All other new nodes will be created by calls to Filter.
From this brief introduction it may sound like there's no reason to use the RDFAnalysis::Node class over the ROOT::RDF::RNode class it wraps. However the new class adds several new concepts omitted from the other. Many of these will be elaborated on in the Node Concepts section
Weights: ROOT::RDF::RNode has no internal concepts of weights being attached to analysis nodes. Weights can be added manually to histogram fill calls, but the default implementation of cutflows cannot be weighted.
Additionally, it is not easy to deal with event-level weights that change throughout the computational tree, for example due to selections on variables that have associated scale factors.
Each node has a branch namer object which keeps track of the branches defined at that point in the analysis. This is mainly used for systematic variations (so will be covered on the dedicated page) but is also used to work out which variables are used in string expressions.
Each Node has its own weight, accessed through the getWeight function. These weights are applied to the weighted cutflow, as well as to any histogram fill calls. Extra arguments can be added to all Filter and Fill calls to set up changing the weights used in those calls. As with Define and Filter calls, these weights can be calculated either with a C++ function-like object or using a JIT compiled string expression.
Additionally a WeightStrategy can be specified. This tells the Node how it should apply this weight. There are two main options to be configured: whether or not the weight added by this node should be multiplied by the weight of the node before it and whether or not this should weight should be applied always or only in 'MC' mode. MC mode is a setting for the whole computational graph, set in the createROOT function, which allows turning off all weights that have the MCOnly WeightStrategy, for example, in order to run on data which does not have those weights. The default value for the WeightStrategy is to be both multiplicative and MC-only.
The Node class has a 'Detail' template parameter. This is used to add extra information (i.e. not histograms) to be stored within the data structure. This defaults to the EmptyDetail class which adds no extra information.
An example of extra information that you might want to add is provided by the CutflowDetail class, which stores information about the number of events passing each filter.
Each node's detail is accessed via the detail function.
You can manually trigger the event loop using the run function. This function can take a template parameter called a Monitor. This object must define an operator() taking a single unsigned int parameter, which is the slot number. This will be provided to the ForEachSlot function of the root of the computation graph (only the nominal variation, if systematic variations are present). Alternatively, a print interval and (optional) total number of events can be provided and the default RDFAnalysis::RunMonitor will be used.
If you do not want to use this feature, then you can trigger the loop implicitly by trying write out from the result of any of the fill actions.
In order to write out the information stored in the tree structure you could manually recurse through the tree and write out how you choose. However, the package also provides the OutputWriter class to write out objects for you.
The OutputWriter mirrors the tree structure of the analysis in the output ROOT file with nested directories representing each step in the computation. The output to be written from each node is decided by adding INodeWriters to the OutputWriter. These decide what information to write from each node and how.
Two of these are pre-written. The TObjectWriter writes the output of all Fill actions. The CutflowWriter converts the information stored in the CutflowDetail into a cutflow, therefore in order to use this class the Detail type of the node must at least inherit from CutflowDetail.
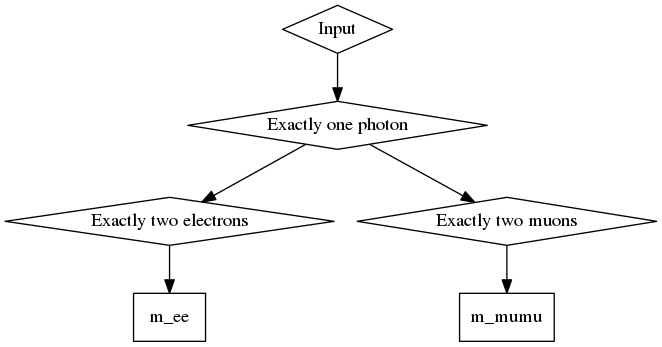
Returning to Zγ example used earlier, assuming that the input TTree contains three branches
containing the kinematics of all photons, electrons and muons passing certain object-level selections, then the corresponding code snippet to create the computational graph and write out the histograms would be (assuming an input ROOT::RDataFrame object called inputDF):
This will produce a computation graph that looks like
 1.8.11
1.8.11 
